Efter att en Dataforskare har valt en målvariabel – t.ex. ”kolumnen” i ett kalkylblad som de vill förutsäga – och slutfört förutsättningarna för att omvandla data och bygga en modell, är ett av de sista stegen att utvärdera modellens prestanda.
Förvirringsmatris
att välja ett resultatmått beror ofta på det affärsproblem som löses., Låt oss säga att du har 100 exempel i din datauppsättning, och du har matat var och en till din modell och fått en klassificering. Den förväntade kontra faktiska klassificeringen kan kartläggas i en tabell som kallas en förvirringsmatris.,0
| negativ (förutsagd) | positiv (förutsagd) | ||
|---|---|---|---|
| negativ (faktisk) | 98 | 0 | |
| positiv (faktisk) | 1 | 1 |
tabellen ovan beskriver en utgång av negativ vs. positiv. Dessa två resultat är ”klasser” av varje exempel., Eftersom det bara finns två klasser kan den modell som används för att generera förvirringsmatrisen beskrivas som en binär klassificerare. (Exempel på en binär klassificerare: spam upptäckt. Alla e-postmeddelanden är spam eller inte spam, precis som all mat är en varmkorv eller inte en varmkorv.)
för att bättre tolka tabellen kan du också se den när det gäller sanna positiva, sanna negativ, falska positiva och falska negativ.,
| Negative (predicted) | Positive (predicted) | |
|---|---|---|
| Negative (actual) | true negative | false positive |
| Positive (actual) | false negative | true positive |
Accuracy
Overall, how often is our model correct?,
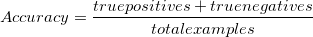 1
1
som heuristisk eller tumregel kan noggrannhet omedelbart berätta om en modell utbildas korrekt och hur den kan fungera generellt. Det ger emellertid inte detaljerad information om dess tillämpning på problemet.
problemet med att använda noggrannhet som din huvudsakliga prestanda är att det inte gör bra när du har en allvarlig klass obalans. Låt oss använda datauppsättningen i förvirringsmatrisen ovan. Låt oss säga att negativen är normala transaktioner och de positiva är bedrägliga transaktioner., Noggrannhet kommer att berätta att du har rätt 99% av tiden i alla klasser.
men vi kan se att för bedrägeriklassen (positiv) har du bara rätt 50% av tiden, vilket innebär att du kommer att förlora pengar. Fan, om du skapade en hård regel som förutspådde att alla transaktioner var normala, skulle du ha rätt 98% av tiden. Men det skulle inte vara en mycket smart modell, eller en mycket smart utvärdering metriska. Det är därför, när din chef ber dig att berätta för dem ” hur exakt är den modellen?”, ditt svar kan vara: ”det är komplicerat.,”
för att ge ett bättre svar behöver vi veta om precision, återkallelse och f1-poäng.
lär dig att tillämpa AI på simuleringar ”
Precision
när modellen förutspår positiva, hur ofta är det korrekt?

Precision hjälper när kostnaderna för falska positiva är höga. Så låt oss anta att problemet innebär upptäckt av hudcancer. Om vi har en modell som har mycket låg precision, kommer många patienter att få veta att de har melanom, och det kommer att inkludera vissa feldiagnoser. Massor av extra tester och stress står på spel., När falska positiva är för höga kommer de som övervakar resultaten att lära sig att ignorera dem efter att ha bombarderats med falska larm.
Recall
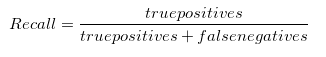
Recall hjälper när kostnaden för falska negativ är hög. Tänk om vi behöver upptäcka inkommande kärnvapenmissiler? En falsk negativ har förödande konsekvenser. Missförstå mig och vi dör allihop. När falska negativ är vanliga, blir du träffad av det du vill undvika. En falsk negativ är när du bestämmer dig för att ignorera ljudet av en kvist som bryter i en mörk skog, och du blir ätit av en björn., (En falsk positiv är att stanna upp hela natten Sömnlös i ditt tält i en kall svett lyssna på varje shuffle i skogen, bara för att inse nästa morgon att dessa ljud gjordes av en jordekorre. Inte kul.) Om du hade en modell som släpper in kärnvapenmissiler av misstag, skulle du vilja kasta ut det. Om du hade en modell som höll dig vaken hela natten eftersom gänget, skulle du vilja kasta ut det också., Om du, som de flesta, föredrar att inte bli ätit av björnen, och inte heller stanna uppe hela natten orolig för chipmunk-larm, måste du optimera för ett utvärderingsmått som är ett kombinerat mått på precision och återkallelse. Ange F1-poängen…
F1-poäng
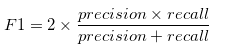
F1 är ett övergripande mått på en modells noggrannhet som kombinerar precision och återkallelse, på det konstiga sättet blandar tillägg och multiplikation bara två ingredienser för att göra en separat maträtt helt och hållet., Det innebär att en bra F1-poäng innebär att du har låga falska positiva och låga falska negativ, så du identifierar riktiga hot korrekt och du störs inte av falska larm. En F1-poäng anses vara perfekt när det är 1, medan modellen är ett totalt fel när det är0.
Kom ihåg: alla modeller är fel, men vissa är användbara. Det innebär att alla modeller kommer att generera några falska negativ, några falska positiva och eventuellt båda., Medan du kan ställa in en modell för att minimera den ena eller den andra, möter du ofta en tradeoff, där en minskning av falska negativ leder till en ökning av falska positiva eller vice versa. Du måste optimera för de resultatmätvärden som är mest användbara för ditt specifika problem.
fotnoter
0) ”förvirring matris” måste vara en av de mest oavsiktligt poetiska termer i alla matematik. Det är den typ av fras som du läser och säger: ”jag lever i en förvirringsmatris. Förvirringsmatrisen av modernitet. Vi är pinballs studsar mellan falska positiva och falska negativ på jakt efter sanningen.,”
1) för enkel Latex formatering som du kan skärmdump och bädda in dina blogginlägg, prova matematik.URL.,TMS