Po wybraniu przez analityka danych zmiennej docelowej – np. „kolumny” w arkuszu kalkulacyjnym, którą chce przewidzieć-i spełnieniu warunków wstępnych przekształcenia danych i zbudowania modelu, jednym z końcowych kroków jest ocena wydajności modelu.
macierz dezorientacji
wybór metryki wydajności często zależy od rozwiązania problemu biznesowego., Załóżmy, że masz 100 przykładów w zbiorze danych, a każdy z nich przekazałeś do swojego modelu i otrzymałeś klasyfikację. Przewidywany vs. rzeczywista klasyfikacja może być wykreślona w tabeli zwanej macierzy zamieszania.,0
| ujemny (przewidywany) | dodatni (przewidywany) | |
|---|---|---|
| ujemny (rzeczywisty) | 98 | 0 |
| dodatni (rzeczywisty) | 1 | 1 |
powyższa tabela opisuje wynik ujemny vs.dodatni. Te dwa wyniki są „klasami” każdego z przykładów., Ponieważ istnieją tylko dwie klasy, model używany do generowania macierzy zamieszania można opisać jako klasyfikator binarny. (Przykład klasyfikatora binarnego: wykrywanie spamu. Wszystkie e-maile są spamem lub nie spamem, tak jak wszystkie jedzenie jest hot dogiem lub nie hot dogiem.)
aby lepiej zinterpretować tabelę, można ją również zobaczyć w kategoriach true positives, true negatives, false positives i false negatives.,
| Negative (predicted) | Positive (predicted) | |
|---|---|---|
| Negative (actual) | true negative | false positive |
| Positive (actual) | false negative | true positive |
Accuracy
Overall, how often is our model correct?,
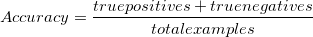 1
1
jako heurystyczna zasada, dokładność może nam natychmiast powiedzieć, czy model jest prawidłowo szkolony i jak może działać ogólnie. Nie podaje jednak szczegółowych informacji dotyczących jego zastosowania do problemu.
problem z używaniem dokładności jako głównego wskaźnika wydajności polega na tym, że nie działa dobrze, gdy masz poważną nierównowagę klasową. Użyjmy zbioru danych w powyższej macierzy zamieszania. Załóżmy, że negatywy to normalne transakcje, a pozytywy to nieuczciwe transakcje., Dokładność pokaże ci, że masz rację w 99% przypadków we wszystkich klasach.
ale widzimy, że dla klasy oszustów (pozytywnie), masz rację tylko 50% czasu, co oznacza, że będziesz tracił pieniądze. Gdybyś stworzył twardą zasadę przewidującą, że wszystkie transakcje są normalne, miałbyś rację w 98% przypadków. Ale to nie byłby bardzo inteligentny model, ani bardzo inteligentny wskaźnik oceny. Dlatego, kiedy twój szef prosi cię, abyś powiedział im :” jak dokładny jest ten model?”, Twoja odpowiedź może brzmieć: „to skomplikowane.,”
aby dać lepszą odpowiedź, musimy wiedzieć o precyzji, przypomnieniu i wynikach f1.
Dowiedz się, jak stosować sztuczną inteligencję do symulacji ”
precyzja
Kiedy model przewiduje pozytywne wyniki, jak często jest poprawny?

precyzja pomaga, gdy koszty fałszywych alarmów są wysokie. Załóżmy więc, że problem polega na wykryciu raka skóry. Jeśli mamy model, który ma bardzo niską precyzję, wielu pacjentów zostanie poinformowanych, że mają czerniaka, a to obejmie pewne błędne diagnozy. Stawką jest mnóstwo dodatkowych testów i stresu., Kiedy fałszywe alarmy są zbyt wysokie, ci, którzy monitorują wyniki, nauczą się je ignorować po bombardowaniu fałszywymi alarmami.
Recall
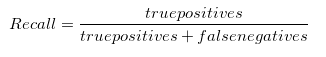
Recall pomaga, gdy koszt fałszywych negatywów jest wysoki. Co jeśli będziemy musieli wykryć nadlatujące pociski nuklearne? Fałszywy negatyw ma druzgocące konsekwencje. Złap to i wszyscy zginiemy. Kiedy fałszywe negatywy są częste, dostajesz hit przez coś, czego chcesz uniknąć. Fałszywy negatywny jest wtedy, gdy zdecydujesz się zignorować dźwięk gałązki łamiącej się w ciemnym lesie i zostaniesz zjedzony przez niedźwiedzia., (Fałszywy pozytywny wynik to nie spanie całą noc w swoim namiocie w zimnym pocie, słuchając każdego przetasowania w lesie, tylko po to, aby następnego ranka uświadomić sobie, że te dźwięki zostały wydane przez wiewiórkę. To nie jest zabawne.) Gdybyś miał model, który przez pomyłkę wpuszczał pociski nuklearne, chciałbyś je wyrzucić. Gdybyś miał model, który nie spał całą noc, bo wiewiórki, też byś go wyrzucił., Jeśli, jak większość ludzi, wolisz nie zostać zjedzonym przez niedźwiedzia, a także nie siedzieć całą noc martwiąc się o alarmy wiewiórek, musisz zoptymalizować wskaźnik oceny, który jest połączoną miarą precyzji i przypomnienia. Wprowadź wynik F1…
wynik F1
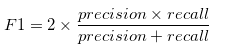
F1 jest ogólną miarą dokładności modelu, która łączy precyzję i przypomnienie, w ten dziwny sposób, że dodawanie i mnożenie po prostu wymieszać dwa składniki, aby całkowicie oddzielne danie., Oznacza to, że dobry wynik F1 oznacza, że masz niskie fałszywe pozytywy i niskie fałszywe negatywy, więc prawidłowo identyfikujesz prawdziwe zagrożenia i nie przeszkadzają ci fałszywe alarmy. Wynik F1 jest uważany za doskonały, gdy jest 1, podczas gdy model jest całkowitą porażką, gdy jest 0.
pamiętaj: wszystkie modele są błędne, ale niektóre są przydatne. Oznacza to, że wszystkie modele będą generować pewne fałszywe negatywy, niektóre fałszywe pozytywy i być może oba., Chociaż możesz dostroić model, aby zminimalizować jeden lub drugi, często napotykasz kompromis, w którym spadek fałszywych negatywów prowadzi do wzrostu fałszywych pozytywów lub odwrotnie. Musisz zoptymalizować wskaźniki wydajności, które są najbardziej przydatne dla konkretnego problemu.
Przypisy
0) „macierz pomieszania” musi być jednym z najbardziej nieumyślnie poetyckich terminów w całej matematyce. To takie zdanie, które czytasz i mówisz: „żyję w macierzy zamieszania. Macierz dezorientacji nowoczesności. Jesteśmy pinballami odbijającymi się między fałszywymi pozytywami i fałszywymi negatywami w poszukiwaniu prawdy.,”
1) dla łatwego formatowania Latex, które można zrzut ekranu i osadzić w postach na blogu, wypróbuj math.url.,TMs