después de que un científico de datos haya elegido una variable objetivo (por ejemplo, la «columna» en una hoja de cálculo que desea predecir) y haya completado los requisitos previos para transformar datos y construir un modelo, uno de los pasos finales es evaluar el rendimiento del modelo.
matriz de confusión
La elección de una métrica de rendimiento a menudo depende del problema del negocio que se está resolviendo., Digamos que tiene 100 ejemplos en su conjunto de datos, y ha alimentado cada uno a su modelo y ha recibido una clasificación. La clasificación predicha vs. REAL se puede trazar en una tabla llamada matriz de confusión.,0
| Negativo (prevista) | Positivo (prevista) | |
|---|---|---|
| Negativos (reales) | 98 | 0 |
| Positivo (real) | 1 | 1 |
La tabla anterior describe una salida de negativos versus positivas. Estos dos resultados son las «clases» de cada ejemplo., Debido a que solo hay dos clases, el modelo utilizado para generar la matriz de confusión se puede describir como un clasificador binario. (Ejemplo de un clasificador binario: detección de spam. Todos los correos electrónicos son spam o no spam, al igual que toda la comida es un perro caliente o no un perro caliente.)
para interpretar mejor la tabla, también puede verla en términos de verdaderos positivos, verdaderos negativos, falsos positivos y falsos negativos.,
| Negative (predicted) | Positive (predicted) | |
|---|---|---|
| Negative (actual) | true negative | false positive |
| Positive (actual) | false negative | true positive |
Accuracy
Overall, how often is our model correct?,
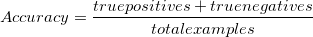 1
1
como heurística, o regla general, la precisión puede decirnos inmediatamente si un modelo está siendo entrenado correctamente y cómo puede funcionar en general. Sin embargo, no proporciona información detallada sobre su aplicación al problema.
el problema con el uso de la precisión como su métrica de rendimiento principal es que no funciona bien cuando se tiene un desequilibrio de clase grave. Usemos el conjunto de datos en la matriz de confusión anterior. Digamos que los negativos son transacciones normales y los positivos son transacciones fraudulentas., La precisión te dirá que tienes razón el 99% del tiempo en todas las clases.
pero podemos ver que para la clase de fraude (positivo), solo tienes razón el 50% del tiempo, lo que significa que vas a perder dinero. Diablos, si crearas una regla dura prediciendo que todas las transacciones eran normales, tendrías razón el 98% de las veces. Pero eso no sería un modelo muy inteligente, o una métrica de evaluación muy inteligente. Por eso, cuando tu jefe te pide que les digas » ¿qué tan preciso es ese modelo?», tu respuesta podría ser: «es complicado.,»
para dar una mejor respuesta, necesitamos saber sobre la precisión, el recuerdo y las puntuaciones de f1.
Aprenda cómo aplicar IA a simulaciones »
precisión
Cuando el modelo predice positivo, ¿con qué frecuencia es correcto?

la Precisión de ayuda cuando los costos de los falsos positivos son altos. Así que asumamos que el problema involucra la detección de cáncer de piel. Si tenemos un modelo que tiene una precisión muy baja, a muchos pacientes se les dirá que tienen melanoma, y eso incluirá algunos diagnósticos erróneos. Muchas pruebas adicionales y estrés están en juego., Cuando los falsos positivos son demasiado altos, aquellos que monitorean los resultados aprenderán a ignorarlos después de ser bombardeados con falsas alarmas.
Recall
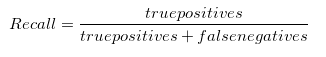
ayuda a Recordar cuando el costo de falsos negativos es alta. ¿Y si necesitamos detectar misiles nucleares entrantes? Un falso negativo tiene consecuencias devastadoras. Si te equivocas, todos moriremos. Cuando los falsos negativos son frecuentes, te golpea lo que quieres evitar. Un falso negativo es cuando decides ignorar el sonido de una ramita que se rompe en un bosque oscuro, y te come un oso., (Un falso positivo es permanecer despierto toda la noche en su tienda de campaña en un sudor frío escuchando cada movimiento en el bosque, solo para darse cuenta a la mañana siguiente de que esos sonidos fueron hechos por una ardilla. No es divertido. Si tuvieras un modelo que dejara entrar misiles nucleares por error, querrías tirarlo. Si tuvieras una modelo que te mantuviera despierta toda la noche porque ardillas, querrías tirarla también., Si, como la mayoría de la gente, prefiere no ser comido por el oso, y también no permanecer despierto toda la noche preocupado por las alarmas de ardilla, entonces necesita optimizar para una métrica de evaluación que es una medida combinada de precisión y recuperación. Introduzca la puntuación de F1
puntuación de F1
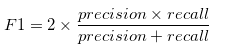
F1 es una medida general de la precisión de un modelo que combina precisión y recuerdo, de esa manera extraña que la adición y la multiplicación solo mezclan dos ingredientes para hacer un plato separado por completo., Es decir, una buena puntuación de F1 significa que tiene bajos falsos positivos y bajos falsos negativos, por lo que está identificando correctamente las amenazas reales y no se ve perturbado por falsas alarmas. Una puntuación de F1 se considera perfecta cuando es 1, mientras que el modelo es un fracaso total cuando es 0.
recuerde: todos los modelos son incorrectos, pero algunos son útiles. Es decir, todos los modelos generarán algunos falsos negativos, algunos falsos positivos, y posiblemente ambos., Si bien puede ajustar un modelo para minimizar uno u otro, a menudo se enfrenta a una compensación, donde una disminución en los falsos negativos conduce a un aumento en los falsos positivos, o viceversa. Tendrá que optimizar las métricas de rendimiento que son más útiles para su problema específico.
notas al pie
0) «matriz de confusión» tiene que ser uno de los Términos poéticos más involuntarios en todas las matemáticas. Es el tipo de frase que lees y dices: «vivo en una matriz de confusión. La matriz de confusión de la modernidad. Somos pinballs rebotando entre falsos positivos y falsos negativos en busca de la verdad.,»
1) para un formato de Latex fácil que puedes capturar e incrustar en tus publicaciones de blog, prueba math.URL.,TMs